Сезонные коэффициенты РЖД на 2019 год
Содержание:
Стоимость пассажирских билетов на поезда в России зависит от сезона. Любой календарный год содержит периоды, когда интерес к поездкам по железной дороге традиционно небольшой. И наоборот, есть такие периоды, когда люди активно путешествуют по стране, покупая билеты на поезда. Для того, чтобы сбалансировать спрос и предложение, РЖД применяет систему специальных коэффициентов, благодаря которым цена билетов меняется в зависимости от сезона. Сезонные коэффициенты РЖД на 2019 год — как меняется стоимость жд билетов в течение года, в какие периоды путешествовать дешевле всего.
О каких особенностях сезонных коэффициентов стоит помнить
Прежде чем мы непосредственно перейдём к таблице сезонных коэффициентов, которыми пользуется РЖД в 2019 году, стоит пояснить некоторые моменты.
Во-первых, сетка коэффициентов отличается для плацкартных вагонов и купе. В целом сезонные коэффициенты в обоих случаях близки, но есть и некоторые отличия.
Во-вторых, ориентироваться на сезонные коэффициенты больше всего имеет смысл в случае с плацкартными и общими вагонами. Дело в том, что подавляющее большинство билетов в купе и СВ компания РЖД продаёт по так называемой системе динамического ценообразования.
Система динамического ценообразования на места в купе и СВ использует гораздо более сложные алгоритмы, чем простое применение сезонных коэффициентов.
Наконец, нужно помнить о том, что коэффициенты применяются только к самому тарифу на проезд. Оплата постельного белья, питания, покупка прессы и других товаров у проводников производится по стандартным расценкам. Эти цены в зависимости от даты никак не меняются.
Сезонные изменения тарифов в плацкартных и общих вагонах в 2019 году
Таблица сезонных коэффициентов стоимости билетов на плацкарт и в общие вагоны в 2019 году делит календарный год на 17 неравных периодов. В этом смысле в текущем году сетка более гибкая — в 2018 году таких периодов было 15. В зависимости от даты, разница в стоимости билета может составлять до 30 процентов.
В зависимости от даты, разница в стоимости билета может составлять до 30 процентов.
| Даты | Кол-во дней | Коэффициент индексации |
|---|---|---|
| 01 января – 08 января | 8 | 1,10 (+10% от базовой цены) |
| 09 января – 21 февраля | 44 | 0,88 (-12% от базовой цены) |
| 22 февраля – 25 февраля | 4 | 1,10 (+10% от базовой цены) |
| 26 февраля – 06 марта | 9 | 0,90 (-10% от базовой цены) |
| 07 марта – 10 марта | 4 | 1,10 (+10% от базовой цены) |
| 11 марта – 25 апреля | 46 | 0,88 (-12% от базовой цены) |
| 26 апреля – 05 мая | 10 | 0,95 (-5% от базовой цены) |
| 06 мая – 13 июня | 39 | 1,05 (+5% от базовой цены) |
| 14 июня – 01 сентября | 80 | 1,20 (+20% от базовой цены) |
| 02 сентября – 15 сентября | 14 | 1,10 (+10% от базовой цены) |
| 16 сентября – 30 сентября | 15 | 1,00 (базовая цена) |
| 01 октября – 31 октября | 31 | 0,90 (-10% от базовой цены) |
| 01 ноября – 04 ноября | 4 | 1,10 (+10% от базовой цены) |
| 05 ноября – 19 декабря | 45 | 0,85 (-15% от базовой цены) |
| 20 декабря – 26 декабря | 7 | 1,00 (базовая цена) |
| 27 декабря – 30 декабря | 4 | 1,15 (+15% от базовой цены) |
| 31 декабря | 1 | 1,00 (базовая цена) |
Самый высокий коэффициент на плацкартные и общие вагоны, таким образом, действует в летний период, с 14 июня по 1 сентября. Летом тариф на 20 процентов выше базовой стоимости жд билетов в РЖД.
Летом тариф на 20 процентов выше базовой стоимости жд билетов в РЖД.
[popper_pro content=»5299″][/popper_pro]
Выгоднее всего в 2019 году будет путешествовать с 5 ноября по 15 декабря. В эти полтора месяца билеты на поезда будут стоить на 15% ниже базовой цены.
Обратите внимание — с 20 января 2019 года РЖД вводит невозвратные билеты на пассажирские поезда. Это позволяет делать новый закон, который вступил в силу с нового года. Невозвратные билеты будут стоить на 5-20% дешевле возвратных. Однако на плацкартные вагоны РЖД пока такие тарифы не распространяет.
Сезонные коэффициенты РЖД на места в вагонах купе и СВ в 2019 году
Таблица коэффициентов в зависимости от сезона для вагонов купе и СВ практически повторяет аналогичную таблицу для плацкартных вагонов. Это те же 17 периодов (в 2019 году их было 19, и разница двух таблиц была очень значительной), и лишь в редких случаях коэффициенты для купе и СВ незначительно отличаются от плацкарта.
| Даты | Кол-во дней | Коэффициент индексации |
|---|---|---|
| 01 января – 08 января | 8 | 1,10 (+10% от базовой цены) |
| 09 января – 21 февраля | 44 | 0,90 (-10% от базовой цены) |
| 22 февраля – 25 февраля | 4 | 1,10 (+10% от базовой цены) |
| 26 февраля – 06 марта | 9 | 0,90 (-10% от базовой цены) |
| 07 марта – 10 марта | 4 | 1,10 (+10% от базовой цены) |
| 11 марта – 25 апреля | 46 | 0,90 (-12% от базовой цены) |
| 26 апреля – 05 мая | 10 | 0,95 (-5% от базовой цены) |
| 06 мая – 13 июня | 39 | 1,05 (+5% от базовой цены) |
| 14 июня – 01 сентября | 80 | 1,20 (+20% от базовой цены) |
| 02 сентября – 15 сентября | 14 | 1,05 (+5% от базовой цены) |
| 16 сентября – 30 сентября | 15 | 1,00 (базовая цена) |
| 01 октября – 31 октября | 31 | 0,90 (-10% от базовой цены) |
| 01 ноября – 04 ноября | 4 | 1,10 (+10% от базовой цены) |
| 05 ноября – 19 декабря | 45 | 0,85 (-15% от базовой цены) |
| 20 декабря – 26 декабря | 7 | 1,00 (базовая цена) |
| 27 декабря – 30 декабря | 4 | 1,15 (+15% от базовой цены) |
| 31 декабря | 1 | 1,00 (базовая цена) |
Места в таких вагонах дороже всего также обходятся летом — с 14 июня по 1 сентября.
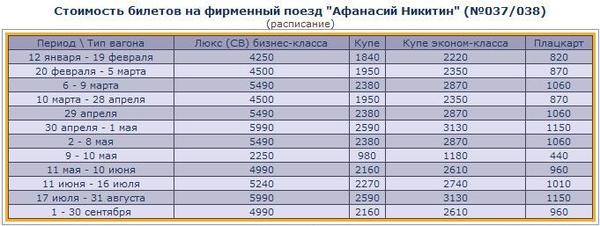
Самый дешевый период тот же, что и для плацкарта — с 5 ноября по 15 декабря. В это время применяется коэффициент 0,85, то есть, билеты стоят на 15 процентов дешевле базовой стоимости.
Ещё раз напомним, что доля билетов в вагоны купе и СВ, стоимость которых формируется только на основе этих коэффициентов, довольно небольшая. В основном такие билеты продаются по системе динамического ценообразования.
Зато для вагонов купе и СВ будут доступны невозвратные билеты. Подробнее о таких билетах — в нашем материале.
Что такое система динамического ценообразования стоимости билетов РЖД в 2019 году
Как поясняет сама компания РЖД, динамическое ценообразование работает в автоматическом режиме. Искусственный интеллект учитывает сотни различных факторов и меняет цену на билет в соответствии с ними. Общий смысл системы в том, что чем выше спрос на билеты, тем дороже его цена.
При этом система сама понимает, насколько высоким может быть спрос на те или иные билеты даже потенциально.

Например, можно хорошо сэкономить на билетах в купе, если ваш поезд отходит или прибывает в не самое удобное время (глубоко ночью) или в неудобные даты. Цена будет зависеть и от конкретного места в самом вагоне. Если вы согласны потерпеть некоторые мелкие неудобства, то сможете купить дешевый билет на поезд РЖД.
Для того, чтобы проверить, какую цену предлагает система на билет в тот или иной поезд, нужно просто воспользоваться поиском билетов. Стоимость сформируется автоматически.
Понравился материал? Расскажите о нём друзьям!
Сезонные коэффициенты РЖД 2023
Например: Что такое электронная регистрация? | Туту!00 |
Изменения цен на железнодорожные билеты в течение года связаны с сезонными коэффициентами. Такую систему ценообразования использует АО «Федеральная пассажирская компания».
Коэффициенты не применяются для поездов, которые участвуют в программе динамического ценообразования.
Купе и люкс (СВ)
|
Даты поездки |
На сколько процентов дешевле или дороже билет |
|
1 января — 8 января |
0% |
|
9 января — 21 февраля |
-15% |
|
22 февраля — 26 февраля |
+10% |
|
27 февраля — 23 марта |
-15% |
|
24 марта — 2 апреля |
+10% |
|
3 апреля — 27 апреля |
-12% |
|
28 апреля — 9 мая |
+10% |
|
10 мая — 8 июня |
+5% |
|
9 июня — 12 июня |
+10% |
|
13 июня — 31 августа |
+20% |
|
1 сентября — 17 сентября |
+10% |
|
18 сентября — 19 октября |
-10% |
|
20 октября — 29 октября |
+5% |
|
|
-10% |
|
3 ноября — 6 ноября |
+10% |
|
7 ноября — 21 декабря |
-15% |
|
22 декабря — 26 декабря |
0% |
|
27 декабря — 28 декабря |
+5% |
|
29 декабря — 30 декабря |
+20% |
|
31 декабря |
0% |
Плацкартные, общие и сидячие вагоны нескоростных поездов
|
Даты поездки |
На сколько процентов дешевле или дороже билет |
|
1 января — 8 января |
0% |
|
9 января — 21 февраля |
-15% |
|
22 февраля — 26 февраля |
+10% |
|
27 февраля — 23 марта |
-15% |
|
24 марта — 2 апреля |
+10% |
|
3 апреля — 27 апреля |
-12% |
|
28 апреля — 9 мая |
+10% |
|
10 мая — 8 июня |
+5% |
|
9 июня — 12 июня |
+10% |
|
13 июня — 31 августа |
+20% |
|
1 сентября — 17 сентября |
+10% |
|
18 сентября — 19 октября |
-10% |
|
20 октября — 29 октября |
+5% |
|
30 октября — 2 ноября |
-10% |
|
3 ноября — 6 ноября |
+10% |
|
7 ноября — 21 декабря |
-15% |
|
22 декабря — 26 декабря |
0% |
|
27 декабря — 28 декабря |
+5% |
|
29 декабря — 30 декабря |
+20% |
|
31 декабря |
0% |
Была ли полезна статья: Да Нет
Какой фактор для вас решающий при покупке авиабилета?
Другие опросы Tutu. ru
ru
Цена билета
Время вылета / Время прилёта
Наличие / отсутствие пересадок
Аэропорт вылета / прилёта (при наличии альтернатив)
Авиакомпания
Тип самолёта
Условия для полёта с детьми
Условия перевозки домашних животных
Условия перевозки багажа и/или спортивного снаряжения
Ответить00
Исследовательский подход к интеллектуальному анализу данных
На этой странице
РезюмеВведениеДоступность данныхКонфликты интересовБлагодарностиСсылкиАвторское правоСтатьи по теме
Использование пропускной способности поезда (TCU), обычно представляемое коэффициентом пассажирской загрузки (PLF), является важным показателем эффективности железнодорожных перевозок. В литературе обычно предпринимаются усилия по улучшению использования пропускной способности путем оптимизации стратегий эксплуатации и управления железной дорогой. Сравнительно мало внимания уделяется анализу факторов, влияющих на TCU, и пониманию стоящих за ним моделей поведения. В этой статье методы исследовательского интеллектуального анализа данных применяются к 3-месячным реальным данным о работе поездов высокоскоростной железной дороги Пекин-Шанхай. Анализ основных компонентов (PCA) проводится для поиска основных компонентов, которые могут эффективно представлять собранные данные. Затем применяются методы кластеризации, чтобы понять уникальные характеристики, влияющие на PLF и схему перемещения. Выводы могут быть использованы в дальнейшем для руководства планированием движения поездов и облегчения принятия более эффективных решений.
Сравнительно мало внимания уделяется анализу факторов, влияющих на TCU, и пониманию стоящих за ним моделей поведения. В этой статье методы исследовательского интеллектуального анализа данных применяются к 3-месячным реальным данным о работе поездов высокоскоростной железной дороги Пекин-Шанхай. Анализ основных компонентов (PCA) проводится для поиска основных компонентов, которые могут эффективно представлять собранные данные. Затем применяются методы кластеризации, чтобы понять уникальные характеристики, влияющие на PLF и схему перемещения. Выводы могут быть использованы в дальнейшем для руководства планированием движения поездов и облегчения принятия более эффективных решений.
1. Введение
Из-за большой протяженности территории и огромного спроса на перевозки в Китае железнодорожный транспорт играет все более важную роль в экономике Китая. В целом китайские высокоскоростные железные дороги предпочтительнее других видов транспорта, особенно для поездок на дальние расстояния. В течение последних пяти лет объем железнодорожных пассажирских перевозок в Китае увеличивался с годовым темпом роста 10%. Согласно статистическим данным за 2016 год, пассажиропоток китайских железных дорог составляет 2,8 миллиарда человек, что на 11% больше, чем в 2015 году. Несмотря на непрерывный рост железнодорожных перевозок в Китае, установлено, что пропускная способность некоторых пассажирских линий недоиспользуется, особенно во время непиковые сезоны. Например, средний коэффициент пассажирской загрузки скоростных поездов в Китае составляет около 60-70%. В крайних случаях число составляет менее 40%. И это побудило исследователей транспорта разработать методы сокращения таких потерь мощности. Оптимизация использования пропускной способности поездов (TCU) является сложной задачей. Проблемы в основном двоякие: (i) схемы пассажирских перевозок весьма случайны и непредсказуемы; (ii) многие факторы могут влиять на TCU, и причинно-следственные связи трудно уловить. Чтобы преодолеть эти проблемы, стало настоятельной задачей выяснить факторы, влияющие на TCU, и выявить поведенческие модели, стоящие за этим.
В течение последних пяти лет объем железнодорожных пассажирских перевозок в Китае увеличивался с годовым темпом роста 10%. Согласно статистическим данным за 2016 год, пассажиропоток китайских железных дорог составляет 2,8 миллиарда человек, что на 11% больше, чем в 2015 году. Несмотря на непрерывный рост железнодорожных перевозок в Китае, установлено, что пропускная способность некоторых пассажирских линий недоиспользуется, особенно во время непиковые сезоны. Например, средний коэффициент пассажирской загрузки скоростных поездов в Китае составляет около 60-70%. В крайних случаях число составляет менее 40%. И это побудило исследователей транспорта разработать методы сокращения таких потерь мощности. Оптимизация использования пропускной способности поездов (TCU) является сложной задачей. Проблемы в основном двоякие: (i) схемы пассажирских перевозок весьма случайны и непредсказуемы; (ii) многие факторы могут влиять на TCU, и причинно-следственные связи трудно уловить. Чтобы преодолеть эти проблемы, стало настоятельной задачей выяснить факторы, влияющие на TCU, и выявить поведенческие модели, стоящие за этим.
Вообще говоря, есть два подхода к пониманию и улучшению использования пропускной способности поездов. Одним из них является подход, основанный на моделях, который применяет аналитические модели для изучения влияния стратегий эксплуатации поездов и управления (например, составление расписаний и продажа билетов) на использование пропускной способности поездов. Второй — это подход интеллектуального анализа данных, который эмпирически анализирует TCU и взаимосвязь между TCU и влиятельными факторами.
Подход, основанный на модели, обычно предполагает наличие причинно-следственных связей и количественных взаимосвязей между выбором железнодорожных пассажиров и факторами эксплуатации/управления поездом. Например, ценообразование и продажа билетов часто рассматриваются как основные стратегии управления, напрямую влияющие на TCU. Для этого исследователи разработали оптимальные модели ценообразования для более эффективного использования поездов и получения дохода. Чжан и др. [1] представил метод дискриминационного ценообразования для улучшения TCU. Вы [2] сформулировали модель нелинейного целочисленного программирования с ограничениями для распределения мест на поезде. Шибата и др. [3], Парк и др. [4] и Бао [5] разработали модели назначения классов мест для увеличения коэффициента использования междугородной железной дороги. Ван и др. [6] изучали проблему распределения мест для оптимизации TCU с учетом поведения пассажиров при случайном выборе. Другая часть исследований направлена на улучшение TCU за счет оптимизации эксплуатационных факторов поезда, таких как расписание поездов и расписание движения. Жа [7], Лан [8] и Ши и др. [9] разработали модели оптимизации движения поездов для максимального использования пропускной способности поездов. Басик и др. [10] предложили новый метод оптимизации плана движения поездов за счет минимизации количества пересадочных рейсов. Zhou et al. также изучали методы улучшения TCU и получения доходов. [11], Кадарсо и соавт. [12], а Робенек и соавт. [13]. В этих исследованиях обычно предполагается, что количество пассажиров и решения о поездках известны и фиксированы.
Вы [2] сформулировали модель нелинейного целочисленного программирования с ограничениями для распределения мест на поезде. Шибата и др. [3], Парк и др. [4] и Бао [5] разработали модели назначения классов мест для увеличения коэффициента использования междугородной железной дороги. Ван и др. [6] изучали проблему распределения мест для оптимизации TCU с учетом поведения пассажиров при случайном выборе. Другая часть исследований направлена на улучшение TCU за счет оптимизации эксплуатационных факторов поезда, таких как расписание поездов и расписание движения. Жа [7], Лан [8] и Ши и др. [9] разработали модели оптимизации движения поездов для максимального использования пропускной способности поездов. Басик и др. [10] предложили новый метод оптимизации плана движения поездов за счет минимизации количества пересадочных рейсов. Zhou et al. также изучали методы улучшения TCU и получения доходов. [11], Кадарсо и соавт. [12], а Робенек и соавт. [13]. В этих исследованиях обычно предполагается, что количество пассажиров и решения о поездках известны и фиксированы. Такие предположения, хотя и идеалистические, довольно распространены в литературе, в основном из-за отсутствия реальных данных (что часто верно для исследований железнодорожных перевозок в Китае).
Такие предположения, хотя и идеалистические, довольно распространены в литературе, в основном из-за отсутствия реальных данных (что часто верно для исследований железнодорожных перевозок в Китае).
В отличие от первого подхода, эмпирический подход применяет методы интеллектуального анализа данных для распознавания образов и извлечения знаний из реальных данных о работе железных дорог. Хотя подходы интеллектуального анализа данных широко применяются во многих транспортных приложениях (например, Zheng et al. [14]; Xie et al. [15]; Anand et al. [16]), такие исследования редки в области железнодорожного транспорта. , в основном из-за отсутствия данных. В литературе можно найти лишь несколько таких примеров. Например, Сюй и др. [17] использовали методы интеллектуального анализа данных для анализа временной последовательности и пространственного влияния совершения поездок и представили новый подход к прогнозированию поездок. Лю и др. [18] применили модель нечеткой кластеризации для анализа поведения пассажиров при поездках и ключевых факторов, влияющих на уровень обслуживания. Чжэн и др. [14] использовали подход интеллектуального анализа данных для анализа пассажиропотока поездов и разработали модель для прогнозирования пассажиропотока. Насколько авторы понимают, ранее не проводилось никакой работы по анализу факторов, влияющих на TCU.
Чжэн и др. [14] использовали подход интеллектуального анализа данных для анализа пассажиропотока поездов и разработали модель для прогнозирования пассажиропотока. Насколько авторы понимают, ранее не проводилось никакой работы по анализу факторов, влияющих на TCU.
В статье представлены два аспекта. (i) Методы исследовательского интеллектуального анализа данных применяются к набору данных, содержащему 3-месячные реальные данные о работе поездов высокоскоростной железной дороги Пекин-Шанхай. Такая информация обычно хранится у железнодорожных компаний и недоступна для широкой публики и научных кругов. (ii) Выявляются и дополнительно анализируются уникальные характеристики, влияющие на PLF и лежащие в их основе модели поведения.
Остальная часть статьи организована следующим образом. В разделе 2 мы кратко опишем источник данных, использованный в исследовании. В разделе 3 представлены ключевые методологии, используемые для интеллектуального анализа данных и извлечения знаний из данных о работе поездов. Эксперимент и численные результаты представлены в разделе 4, а заключительные замечания — в разделе 5.
Эксперимент и численные результаты представлены в разделе 4, а заключительные замечания — в разделе 5.
2. Описание данных
Информационная система управления пассажирскими перевозками на железнодорожном транспорте — это официальная система управления железнодорожными перевозками, поддерживаемая Китайской железнодорожной корпорацией (CRC). Набор данных, использованный для этого исследования, был получен из системы, которая содержит информацию о работе высокоскоростной железной дороги Пекин-Шанхай за 3 месяца. Эта железнодорожная линия является важнейшим транспортным коридором, соединяющим два крупнейших города Китая. Железнодорожная линия имеет общую длину 1318 км и проходит через 24 станции. Эти 24 станции можно дополнительно разделить на категории в зависимости от их административного уровня, как показано в таблице 1. В целом, более высокий уровень указывает на более высокую численность населения и более высокий социально-экономический статус. Набор данных был дополнительно обработан для извлечения 33 репрезентативных операционных признаков. Описание функций можно найти в таблице 2.
Описание функций можно найти в таблице 2.
Эксплуатационные характеристики включают коэффициент пассажирской загрузки (PLF), который непосредственно указывает на загрузку поезда, дату, стратегию продажи билетов (TS), продолжительность рейса (RDR), время отправления (DT), тип поезда (TT), количество остановки (NS), расстояние пробега (RDI), расписание остановок (SS), скорость движения (RS) и коэффициенты нагрузки (LCs) для всех участков вдоль железнодорожного пути. Авторам известно о других факторах, таких как цели поездки и социально-экономический статус пассажиров, которые также могут повлиять на TCU, но такая информация отсутствует в базе данных CRC. Поскольку цены на билеты остаются стабильными в течение исследуемого периода, ценообразование не считается важным фактором в исследовании.
В литературе PLF используется для оценки TCU, а коэффициенты нагрузки используются для оценки использования мощности секций. В этом исследовании важными характеристиками считаются как PLF, так и коэффициенты нагрузки. Пусть C обозначает вместимость поезда (т. е. количество мест), D — пробег, S — количество станций. PLF можно выразить как (1). Аналогичное определение можно найти у Bao et al. [19, 20] .
Пусть C обозначает вместимость поезда (т. е. количество мест), D — пробег, S — количество станций. PLF можно выразить как (1). Аналогичное определение можно найти у Bao et al. [19, 20] .
Здесь и указывают объем пассажирского ОД и длину участка между станциями и соответственно. Поскольку OD для пассажиров недоступен из набора данных, эквивалентно, мы можем использовать секционные пассажиропотоки (для расчета PLF, как в
Обратите внимание, что коэффициент нагрузки сечения известен как согласно [21]. Таким образом, мы можем вывести следующую взаимосвязь между PLF и коэффициентами секционной нагрузки, как в
На рисунке 1 мы сначала показываем агрегированную статистику собранных данных. На рис. 1(а) показано распределение PLF и линия тренда. На рис. 1(б) показаны средние коэффициенты нагрузки восходящего и нисходящего поездов. Можно обнаружить, что средний PLF снижается в течение всего периода исследования, а схема передвижения может характеризоваться двумя сегментами поездок, включая s1(BJS)-s12(XZE) и s12(XZE)-s24(SHHQ).
3. Методология
В контексте статистического анализа и интеллектуального анализа данных исследовательский анализ данных (EDA) представляет собой процесс детективной работы, который не требует проверки заранее определенной гипотезы. Скорее, роль EDA состоит в том, чтобы исследовать данные всеми возможными способами, пока не будет найдена правдоподобная «история» данных. Формальные определения EDA и исследовательского интеллектуального анализа данных можно найти у Tukey [22] и Yu [23]. В этом разделе применяются исследовательские подходы к интеллектуальному анализу данных, чтобы получить представление о структуре данных и лежащих в их основе схемах путешествий. Во-первых, анализ основных компонентов (PCA) используется для выбора наиболее важных функций (называемых основными компонентами) для представления данных о работе поезда. Во-вторых, мы используем методы кластеризации, чтобы обнаружить внутреннюю связь между TCU и основными компонентами.
3.1. Анализ главных компонентов
PCA — широко используемый метод уменьшения размерности и выбора признаков [24]. Здесь мы используем PCA для поиска низкоранговой аппроксимации эксплуатационных данных поезда. На этом этапе исходные 33 функции движения поезда преобразуются в меньший набор новых переменных, называемых главными компонентами (PC), которые, по идее, сохраняют такое же количество вариаций, как и в исходном наборе данных. ПК являются некоррелированными переменными, упорядоченными по их дисперсии от наибольшей дисперсии до наименьшей.
Здесь мы используем PCA для поиска низкоранговой аппроксимации эксплуатационных данных поезда. На этом этапе исходные 33 функции движения поезда преобразуются в меньший набор новых переменных, называемых главными компонентами (PC), которые, по идее, сохраняют такое же количество вариаций, как и в исходном наборе данных. ПК являются некоррелированными переменными, упорядоченными по их дисперсии от наибольшей дисперсии до наименьшей.
Предположим, что матрица объектов с нулевым центром содержит наборы образцов (называемые точками данных) и p=33 объектов, помеченных как . — дисперсионно-ковариационная матрица. Обозначим и как ранжированные собственные значения и связанные с ними собственные векторы , где и . Цель PCA состоит в том, чтобы определить новый набор репрезентативных переменных , каждая из которых рассматривается как линейная комбинация исходных признаков, как в и
где коэффициенты линейных преобразований и . Максимизируя дисперсию переменных, можно легко показать, что и . Переменные называются ПК. Далее определите уровень вклада как , который представляет собой процент вариации, объясняемый выбранными ПК. Таким образом, мы можем получить разумное представление исходных данных (например, с уровнем вклада 80%) всего с несколькими ПК. Можно провести корреляционный анализ, чтобы увидеть корреляции между ПК и исходными функциями.
Переменные называются ПК. Далее определите уровень вклада как , который представляет собой процент вариации, объясняемый выбранными ПК. Таким образом, мы можем получить разумное представление исходных данных (например, с уровнем вклада 80%) всего с несколькими ПК. Можно провести корреляционный анализ, чтобы увидеть корреляции между ПК и исходными функциями.
3.2. Кластерный анализ
Кластеризация нечетких c-средних (FCM; см. [25]) затем используется для обнаружения взаимосвязи между главными компонентами (PC) и коэффициентом пассажирской загрузки (PLF). Цель кластеризации состоит в том, чтобы поместить «похожие» образцы в одну и ту же группу и изучить закономерности, отражаемые разными группами. Пусть , — преобразованные образцы поездов, каждый из которых имеет особенности; т.е. FCM используется для разделения этих выборок на кластеры; каждый кластер характеризуется своим средним значением выборки, называемым центроидом. Этот подход является стандартным и широко используемым подходом к интеллектуальному анализу данных и доказал свою эффективность для извлечения знаний из многомерного набора данных [26]. FCM не требует, чтобы каждая точка данных принадлежала ровно одному кластеру; поэтому он обычно превосходит методы жесткой кластеризации (например, K-средних) для перекрывающихся наборов данных. Задачей FCM является минимизация суммирования взвешенных расстояний между каждой выборкой и центроидом каждого кластера, как в формулировке (6), т. е. минимизация различий выборок внутри одного кластера.
Нечеткий коэффициент, определяющий нечеткий вес результатов кластеризации; – степень принадлежности к кластеру; и является центроидом кластера в -мерном пространстве признаков. Обратите внимание, что расстояние между каждым образцом и центроидом каждого кластера измеряется евклидовой нормой, как в (7), где представляет -й признак i -го преобразованного образца и обозначает положение центроида в k — й размер.
Нечеткое разбиение выполняется путем итеративной оптимизации целевой функции, показанной в (6), с обновленной степенью принадлежности, рассчитанной с использованием
Центр тяжести кластера можно обновить, используя
Итеративный алгоритм завершается, когда , где ε — критерий остановки. — матрица центроида кластера на итерации . Эта процедура также по крайней мере сходится к точке локального минимума . Примечательно, что в вышеупомянутой процедуре не указывается количество кластеров; оптимальное количество кластеров определяется на основе коэффициента Се-Бени [27] и коэффициента разделения [28] в эксперименте.
4. Эксперимент и численные результаты
Сначала мы разделяем образцы на восходящие и нисходящие потоки. Затем к этим двум наборам данных применяются методы PCA и кластеризации. В результате разведочного анализа данных сделано несколько интересных выводов, которые обсуждаются в этом разделе.
4.1. Нисходящие поезда
Нисходящие поезда представляют собой поезда, следующие из Южного Пекина (s1) в Шанхай Хунцяо (s24). PCA был впервые применен к набору данных. Совокупный уровень вклада (по отношению к ПК) показан на рисунке 2 (а). Установлено, что ПК1-ПК3 составляют более 80% общей изменчивости. На рисунке 2(b) показано, что PC1 сильно коррелирует (степень корреляции > 0,6) с несколькими характеристиками, включая продолжительность пробега (RDR), расстояние пробега (RDI), схему остановки (SS) и секционную нагрузку. коэффициенты , от станции Jinan West (JNW) до станции Shanghai Hongqiao (SHHQ). Некоторые другие функции, такие как дата и скорость выполнения (RS), не сильно коррелируют с PC1. Это указывает на то, что PC1 и сильно коррелированные признаки объясняют наибольшую вариацию данных.
В следующем эксперименте мы используем PC1 и PLF для нечеткой кластеризации c-средних. Найдены два оптимальных кластера, которые представлены на рис. 3(а). Можно заметить, что более высокий PLF связан с более высоким PC1. Поскольку PC1 положительно коррелирует с RDR, RDI, SS и , , можно сделать вывод, что большее расстояние пробега/время в пути, более высокий уровень схемы остановок (т. е. меньше остановок) и более высокие коэффициенты секционной нагрузки от станции JNW до SZN станции связаны с поездами более высокого PLF. Такой вывод можно подтвердить, построив распределение этих исходных признаков для каждого кластера, как показано на рисунках 3(b), 3(c), 3(d) и 4.
Также замечено, что кластер B в На рис. 3(а) показаны разветвленные линии с разным наклоном, представляющие разные скорости PLF к PC1. Для дальнейшего анализа шаблона мы использовали RDI в качестве суррогата PC1 и применили модель кластеризации, используя PLF/RDI в качестве единственной функции. Результаты на рисунке 5 показали пять кластеров, которые соответствуют пяти линейным линиям, показанным на рисунке 3 (а). Результаты показывают, что предельный эффект RDI постепенно уменьшается; т. е. замена поездов ближнего следования на поезда средней дальности представляется более выгодной (с точки зрения прироста PLF) по сравнению с заменой поездов средней дальности на поезда дальнего следования. Этот вывод можно использовать для планирования расписания поездов.
4.2. Восходящие поезда
Совокупный уровень вклада каждого ПК показан на рисунке 6(a) для восходящих поездов из Шанхая Хунцяо (s24) в Южный Пекин (s1). Затем мы провели кластерный анализ с использованием PLF, PC1 и PC2. Установлено, что оптимальное количество кластеров равно 3, как показано на рис. 6(б) .
На рис. 7 показаны исходные признаки, сильно коррелирующие с ПК1 и ПК2. В частности, установлено, что , RDI и SS сильно коррелируют с PC1; LC () и время отправления (DT) сильно коррелируют с PC2. Для восходящих поездов можно сделать несколько выводов о схеме движения TCU и пассажиров.
Как видно на рис. 6(b), по сравнению с образцами с более низким PLF (кластер B), поезда с более высоким PLF (кластер A) связаны с большим PC1, что указывает на то, что более высокий SS (меньше остановок), более длинный RDI и более высокий LC приводят к лучшему использованию пропускной способности поезда. Это дополнительно подтверждается на рисунках 8(a), 8(b) и 8(c). Такой вывод согласуется с нисходящими поездами.
Результат на рисунке 6(b) также показывает, что кластер C, отделенный от двух других кластеров, имеет большие различия в размерности PC2. При дальнейшем анализе распределений DT (суррогата PC2) обнаружено, что кластер C связан с образцами, которые имеют более раннее время отправления (как показано на рисунке 8 (d)) и проходят меньшее количество участков/более короткое расстояние (как показано на рис. 8(d)). показано на рисунках 8(b) и 8(c)). Эти выборки соответствуют дополнительным (временным) поездам ближнего следования, которые отправляются рано утром. Затем мы повторно запускаем модели PCA и кластеризации только для образцов кластера C, чтобы дополнительно изучить закономерности этих дополнительных поездов. Результаты показаны на рисунке 9..
Показано, что PLF и LCs () сильно коррелируют с PC1; дата, DT и LC () сильно коррелируют с PC2. Как и на рисунке 9(а), кластер C-2 и кластер C-3 находятся в более высокой области PC1; кластер C-1 находится в нижней области PC1. Обнаружено, что начало этого квартала и раннее DT связаны с более высоким PLF с более высокими LC (), как показано кластером C-2; конец этого квартала и относительно позднее DT также приводят к более высокому PLF с более высокими LC. Примечательно, что начало квартала соответствует «Золотой неделе» (китайскому национальному празднику), а конец квартала близок к Новому году. Таким образом, дополнительные поезда с ранним или поздним временем отправления лучше используются в праздничные сезоны по сравнению с другими сезонами.
Тщательно изучив рисунок 8(с), мы обнаружили, что основной достопримечательностью поездов группы А является Пекин (поскольку коэффициент загрузки высок на участке 1), а основной достопримечательностью поездки поездов группы В является город Сюйчжоу (станция XZE), город среднего уровня. Комбинируя закономерности на рисунках 8(a) и 8(c), можно сделать вывод, что пассажиров, направляющихся в Пекин, предпочитают выбирать поезда с меньшим количеством остановок, скорее всего, из-за более высокой ценности времени.
В этом документе предлагается исследовательский подход к интеллектуальному анализу данных для выявления влиятельных особенностей TCU и понимания моделей движения с использованием реальных данных о работе поездов. В статье сообщается о нескольких интересных выводах, кратко изложенных ниже. (1) Установлено, что дистанция пробега и схема остановки тесно связаны с TCU. Согласно конкретному набору данных, поезда с более длинным пробегом и меньшим количеством остановок приводят к более высокому TCU. (2) Предельный эффект расстояния поездки уменьшается с точки зрения прироста TCU. Преобразование поездов ближнего следования в поезда средней дальности более выгодно, чем преобразование поездов средней дальности в поезда дальнего следования. — пиковые сезоны используются не так хорошо. (4) Пассажиры крупных городов предпочитают поезда с меньшим количеством остановок. Такой поведенческий паттерн можно объяснить их ценностью во времени.
Эти выводы, хотя и относящиеся к конкретному случаю, показали, что предлагаемый подход является полезным инструментом для интеллектуального анализа данных и извлечения знаний из эксплуатационных данных поезда, и его можно использовать для облегчения принятия более разумных решений для эксплуатации поезда и управления им.
Доступность данных
Данные, использованные для поддержки результатов этого исследования, можно получить у соответствующего автора по запросу.
Конфликт интересов
Авторы заявляют об отсутствии конфликта интересов.
Благодарности
Первый и четвертый авторы поддерживаются Национальной ключевой программой исследований и разработок Китая (проект № 2017YFB1200701).
Ссылки
X.M. Zhang, D.M. Zhao, and S.D. Wen, «Управление доходами от железнодорожных билетов», Железнодорожный транспорт и экономика , vol. 28, нет. 7, стр. 7–9, 2006.
Посмотреть по адресу:
Google Scholar
P.-S. Вы, «Эффективный вычислительный подход к задачам бронирования билетов на поезд», Европейский журнал операционных исследований , том. 185, нет. 2, стр. 811–824, 2008 г.
Посмотреть по адресу:
Сайт издателя | ученый Google | MathSciNet
Ж.-Ю. Ли, Дж.-Х. Чанг и Б. Сон, «Анализ времени разрешения инцидентов на корейских автострадах с использованием модели структурного уравнения», Журнал Восточно-Азиатского общества транспортных исследований , том.
 8, pp. 1850–1863, 2010.
8, pp. 1850–1863, 2010.Посмотреть по адресу:
Google Scholar
C. Park and J. Seo, «Управление запасами мест для последовательных нескольких рейсов с поведением выбора клиента», Компьютеры и промышленное проектирование , том. 61, нет. 4, стр. 1189–1199, 2011.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Ю. Бао, Теория и методы управления запасами мест на железнодорожном транспорте , Пекинский университет Цзяотун, 2014.
X. Ван, Х. Ван и X. Чжан, «Стохастические модели распределения мест» для пассажирских железнодорожных перевозок по выбору клиента», Transportation Research Part E: Logistics and Transportation Review , том. 96, стр. 95–112, 2016 г.
Посмотреть по адресу:
Сайт издателя | Google Scholar
У.
С. Чжа и З. Фу, «Исследование метода оптимизации плана сквозного пассажирского поезда», Журнал Китайского железнодорожного общества , том. 22, нет. 5, стр. 1–6, 2000.Посмотреть по адресу:
Google Scholar
С. М. Лан, «Исследование плана пассажирского поезда для высокоскоростной железной дороги Пекин-Шанхай», Железнодорожный транспорт и экономика , том. 24, нет. 5, стр. 31–34, 2002.
Посмотреть по адресу:
Google Scholar
Ф. Ши, Л.-Б. Дэн, X.-Х. Ли и К.-Г. Фанг, «Исследование планов пассажирских поездов для выделенных линий пассажирского движения», Журнал Китайского железнодорожного общества , том. 26, нет. 2, pp. 16–20, 2004.
Посмотреть по адресу:
Google Scholar
М. Р. Бассик, Т.
Линднер и М. Е. Люббекке, «Быстрый алгоритм для оптимальных планов линий с близкими затратами», Математические методы исследования операций , вып. 59, нет. 2, стр. 205–220, 2004.Посмотреть по адресу:
Сайт издателя | ученый Google | MathSciNet
W.-L. Чжоу, Ф. Ши, Ю. Чен и Л.-Б. Дэн, «Метод комплексной оптимизации плана и схемы движения поездов для сети выделенных пассажирских линий», Tiedao Xuebao/Journal of the China Railway Society , vol. 33, нет. 2, стр. 1–7, 2011.
Посмотреть по адресу:
Google Scholar
Л. Кадарсо, А. Марин, Дж. Л. Эспиноса-Аранда и Р. Гарсия-Роденас, «Расписание поездов на высокоскоростных железных дорогах: учет конкурентных эффектов», Procedia — Social and Behavioral Sciences , vol. 162, стр. 51–60, 2014.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Т.
Робенек, С. Шариф Азаде, Ю. Макнун и М. Бирлер, «Гибридная цикличность: сочетание преимуществ циклического и нециклического расписания», Transportation Research Part C: Emerging Technologies , том. 75, стр. 228–253, 2017.Посмотреть по адресу:
Сайт издателя | Google Scholar
Д. Чжэн, Ю. Ван, П. З. Тан и Ю. П. Ву, «Применение интеллектуального анализа данных в прогнозировании пассажиропотока на железной дороге», Advanced Materials Research , vol. 834–836, стр. 958–961, 2013 г.
Посмотреть по адресу:
Сайт издателя | Google Scholar
X.-L. Се и X.-Ф. Гу, «Исследование модели интеллектуального анализа данных интеллектуального транспорта на основе гранулярных вычислений», Международный журнал безопасности и ее приложений , том. 10, нет. 7, стр. 281–286, 2016.
Просмотр по адресу:
Google Scholar
С.
Ананд, П. Падманабхам, А. Говардхан и Р. Х. Кулкарни, «Обширный обзор методов интеллектуального анализа данных и моделей кластеризации». для интеллектуальной транспортной системы», Journal of Intelligent Systems , vol. 27, нет. 2, стр. 263–273, 2018 г.Посмотреть по адресу:
Сайт издателя | Академия Google
В. Сюй, Х. К. Хуан и Ю. Цинь, «Изучение метода прогнозирования пассажиропотока на железной дороге на основе пространственно-временного сбора данных», Журнал Северного университета Цзяотун , стр. 401–405, 2004.
Посмотреть по адресу:
Google Scholar
Дж. Лю и Н. Чжан, «Эмпирическое исследование поведения пассажиров междугородних высокоскоростных поездов на основе модели нечеткой кластеризации», Цзяотун Юньшу Ситун Гунчэн Ю Синьси/Journal of Transportation Системная инженерия и информационные технологии , том.
12, нет. 6, pp. 100–105, 2012.Посмотреть по адресу:
Google Scholar
Ю. Бао, Дж. Лю, М.-С. Ма и Л.-Ю. Мэн, «Подход к управлению вложенными местами для высокоскоростных поездов», Tiedao Xuebao/Journal of the China Railway Society , vol. 36, нет. 8, pp. 1–6, 2014.
Посмотреть по адресу:
Google Scholar
Ю. Бао, Дж. Лю, М.-С. Ма и Л.-Ю. Мэн, «Методы управления количеством мест для пассажирских железных дорог Китая», Журнал Центрального Южного Университета , том. 21, нет. 4, стр. 1672–1682, 2014.
Посмотреть по адресу:
Сайт издателя | Google Scholar
С. Г. Арул, «Методы монетизации колебаний коэффициента загрузки и выбросов парниковых газов на пассажиро-милю авиакомпаний», Transportation Research Part D: Transport and Environment , vol.
32, стр. 411–420, 2014.Посмотреть по адресу:
Сайт издателя | Google Scholar
Дж. В. Тьюки, Исследовательский анализ данных , Аддисон-Уэсли, Бостон, Массачусетс, США, 1977.
К. Хо Ю, «Исследовательский анализ данных в контексте интеллектуального анализа данных и повторной выборки», Международный журнал психологических исследований , об. 3, нет. 1, с. 9, 2010.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Х. Абди и Л. Дж. Уильямс, «Анализ основных компонентов», Междисциплинарные обзоры Wiley: вычислительная статистика , том. 2, нет. 4, стр. 433–459, 2010.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Дж. К. Данн, «Нечеткий родственник процесса ISODATA и его использование для обнаружения компактных хорошо разделенных кластеров», Journal of Cybernetics , vol.
3, нет. 3, стр. 32–57, 1973.Посмотреть по адресу:
Сайт издателя | ученый Google | MathSciNet
К. В. Ван и Дж. Х. Дженг, «Сжатие изображений с использованием PCA с кластеризацией», Международный симпозиум по интеллектуальным системам обработки сигналов и связи , vol. 41, нет. 11, стр. 458–462.
Посмотреть по адресу:
Google Scholar
X. L. Xie и G. Beni, «Мера достоверности для нечеткой кластеризации», IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 13, нет. 8, стр. 841–847, 1991.
Посмотреть по адресу:
Сайт издателя | Google Scholar
Н. Захид, М. Лимури и А. Эссаид, «Новая кластерная достоверность для нечеткой кластеризации», Распознавание образов , том.
32, нет. 7, стр. 1089–1097, 1999.Посмотреть по адресу:
Сайт издателя | Google Scholar
Copyright
Copyright © 2018 Fanxiao Liu et al. Это статья с открытым доступом, распространяемая в соответствии с лицензией Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии надлежащего цитирования оригинальной работы.
Топливная эффективность — CSX.com
Fuel Efficiency
По данным AAR, перевозка грузов по железной дороге в 4 раза более экономична по топливу, чем перевозка грузов по шоссе. Поезда CSX могут перевезти тонну груза примерно на 492 мили на одном галлоне топлива. Эффективное использование топлива означает сокращение выбросов парниковых газов на нашу планету. (Узнайте больше на веб-сайте Ассоциации американских железных дорог http://www. aar.org/.)
Вот формула для нашего рейтинга топливной эффективности за 2018 год: (из отчета CSX R-1 за 2018 год)
• График 750, строки 1+3 (строка 4), Потребление дизельного топлива (фрахт + коммутация) = 423 998 863 галлона 208 712 027 000 RTM / 423 998 863 галлона) = 492 RTM/галлон
За последнее десятилетие компания CSX инвестировала более 2,8 млрд долларов США в повышение эффективности использования топлива локомотивами и сокращение соответствующих выбросов.
Расчет эффективности использования топлива
Тонна-миля на галлон — это единица измерения, используемая для описания эффективности перевозки грузов различными видами транспорта.
Железнодорожная отрасль отслеживает и сообщает о доходах в тонно-милях в «Годовом отчете для Совета по наземному транспорту» (обычно называемом отчетом R1). Годовая стоимость грузовых тонно-миль указывается в Приложении 755, строка 110 Отчета R1. Железнодорожная отрасль также отслеживает и сообщает о годовом использовании топлива в Отчете R1, График 750, строка 4. Эти два сообщаемых значения используются для определения значения эффективности поезда в масштабах всей системы.
Например, в 2018 году количество тонно-миль грузов, указанное в отчете R1, = 208 712 027 000 тонно-миль, а объединенное количество магистральных перевозок и стрелочных переводов CSX 2018 сообщило об использовании топлива = 423 998 863 галлонов.
Показатель эффективности поездов в масштабах всей системы CSX 2018 года равен:
208 712 027 000 тонно-миль / 423 998 863 галлона = 492 тонно-миля на галлон.
Другими словами, поезда CSX в среднем могут перевезти тонну груза почти на 500 миль на галлоне топлива, исходя из нашего дохода в тонно-милях за 2018 год и расхода топлива в 2018 году.
Аналогичным образом можно оценить топливную экономичность грузового автомобиля. Например, дизельный грузовик большой грузоподъемности, перевозящий 19 тонн груза на расстояние 500 миль, потребляет примерно 71 галлон дизельного топлива, предполагая среднюю экономию топлива грузовика на 7 миль на галлон и типичную полезную нагрузку грузовика 19 тонн.